Cloud High Availability Plugin
The SSR-cloud-ha plugin provides High Availability (HA) functionality for the SSR Networking Platform deployed in the cloud. HA for SSR routers in a non-cloud environment uses traditional techniques such as VRRP and GARP which both rely on a virtual MAC and virtual IP. In cloud environments such as AWS, Azure, etc., any techniques that rely on broadcast and multicast are not supported. This plugin uses node health metrics sent over SVR, as well as cloud API interactions to perform failovers in these cloud environments.
The instructions for installing and managing the plugin can be found here.
Supported Solutions
| Solution Name | solution-type | Available In Version |
|---|---|---|
| Azure VNET | azure-vnet | 2.0.0 |
| Azure Loadbalancer | azure-lb | 2.0.0 |
| Alicloud VPC | alicloud-vpc | 3.0.0 |
Version Restrictions
The router component can only be installed on versions of SSR which support provisional state on device interfaces. This is necessary for the plugin to be able to prevent asymmetrical routing.
The versions of SSR that support this feature have a Provides: 128T-device-interface-api(1.0), so it can be checked ahead of time by performing a rpm -q --whatprovides 128T-device-interface-api(1.0) to see if the currently installed 128T satisfies this requirement or dnf list --whatprovides 128T-device-interface-api(1.0) to see all versions of SSR that satisfy this requirement.
Plugin Behavior
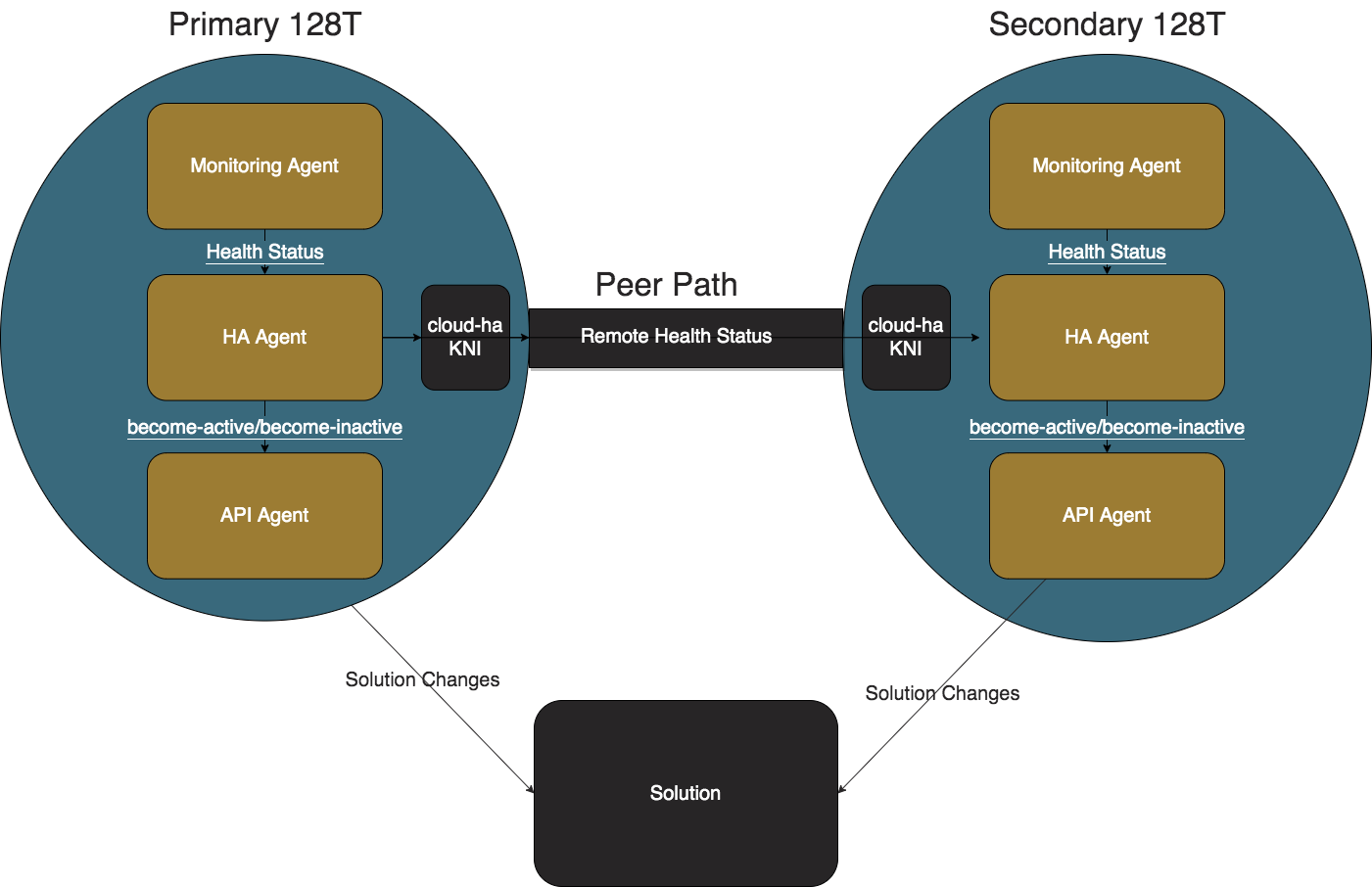
Monitoring Agent
The job of the Monitoring Agent is to produce and transmit health status messages. The Monitoring Agent collects the administrative status, operational status, and mac address of all of the configured redundant interfaces and additional interfaces at one second intervals. The health status is then sent via an HTTP POST to the IP address of the cloud-ha interface where the HA Agent is listening on port 12800.
HA Agent
The job of the HA Agent is to process the health status messages from the the local Monitoring Agent and determine the health status for performing failover operations. For an interface to be healthy, it must be administratively and operationally up. For a node to be healthy, it must have at least one healthy redundant-interface. If there are additional interfaces configured, then the node must have at least one healthy additional-interface.
The following flow diagram summarizes the process followed by the HA Agent using information supplied by the Monitoring Agent, and resulting in interactions with the API Agent.
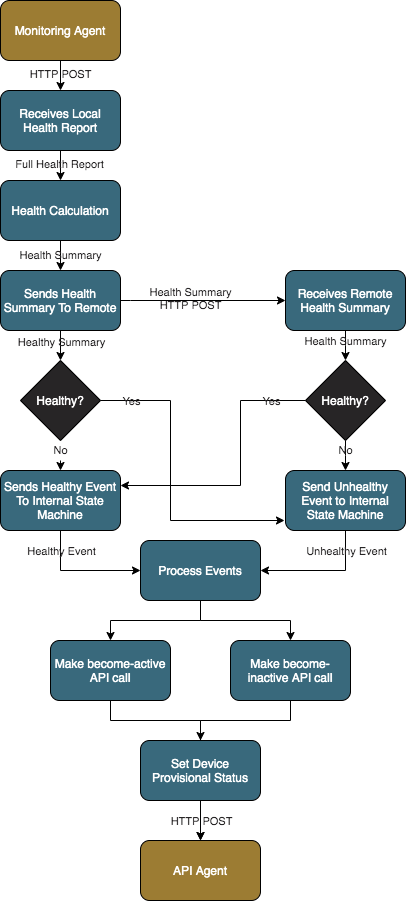
An HA Agent configured with a priority of 1 will be defined as the Primary node; a priority of 2 becomes the Secondary node.
- Primary: This node is preferred to be active except when the local node is unhealthy.
- Secondary: This node is preferred to become active only when the local node is healthy and the remote node is unhealthy or unreachable.
The internal state machines wait for the value set in seconds in up-holddown-timeout before considering a node healthy. If at any point during that wait the HA Agent receives an unhealthy status, the timeout will be reset and the node is considered unhealthy.
The internal state machines wait for the peer-reachability-timeout after every health status before considering the node unreachable. The timer is reset if a health report is processed before the timeout expires.
When the HA Agent determines that a node must become active, the first active redundant interface's mac address and the list of configured prefixes are sent to the API Agent's appropriate REST endpoint. The HA Agent changes the provisional status of the configured redundant-interface to Up.
API Agents
The job of the API Agent is to perform failover actions specific to the cloud provider and the chosen solution.
Azure Loadbalancer
A solution-type of azure-lb can be used to enable the Azure Loadbalancer API agent. This solution requires an Azure Loadbalancer to be configured using an HTTP probe on the probe-port with backend pools pointing towards the redundant interfaces.
Probe example:

Backend Pool example:

The Azure Loadbalancer sends a health probe to the redundant SSR's redundant interfaces. These probes are routed through the cloud-ha interface, through a 128T-azure-lb-nginx instance, and down to the Azure Loadbalancer API Agent.
The Azure Loadbalancer API Agent responds to the probes with a 200 status code when the current node is active and a 500 code when its inactive. A probe to the inactive node will not reach the SSR when the redundant interfaces are set provisionally down.
Azure VNET
A solution-type of azure-vnet can be used to enable the Azure VNET API agent. It requires an Azure Route Table setup on the same VNET as the redundant interfaces. The Virtual Machines where these members are running must be granted the following permissions in order for the route updates to work correctly:
- Microsoft.Network/routeTables/read
- Microsoft.Network/networkInterfaces/read
- Microsoft.Network/routeTables/routes/*/write
- Microsoft.Network/routeTables/routes/read
- Microsoft.Compute/virtualMachines/read
- Microsoft.Network/virtualNetworks/read
The agent finds all of the route tables within the VNET using the Azure REST APIs. When a redundant interface becomes active, the agent updates the route tables for all the configured prefixes to point to that interface. The solution is designed to be idempotent, so the peer member's redundant interface will now be inactive. There is no update to the route table needed when becoming inactive.
Microsoft.Network/virtualNetworks/read is only necessary when the plugin should discover and modify peer VNET route tables. This feature can be enabled by configuring include-peer-vnets to true.
To prevent routing loops, the solution will not update the Azure Route Tables assigned to a subnet that has an activating node's network interface.
Alicloud VPC
A solution-type of alicloud-vpc can be used to enable the Alicloud VPC API agent. It requires an Alicloud Route Table setup on the same VNET as the redundant interfaces.
Since the deployment of Juniper SDWAN HA requires granting RAM role permissions, you need to add a RAM username for this under your current Alicloud account and grant the following permissions. The Virtual Machines where these members are running must be granted with the RAM role with following permissions in order for the route updates to work correctly:
- AliyunECSFullAccess
- AliyunVPCFullAccess
The agent finds all of the route tables within the Alicloud VPC using the Alicloud REST APIs. When a redundant interface becomes active, the agent updates the route tables for all the configured prefixes to point to that interface. The solution is designed to be idempotent, so the peer member's redundant interface will now be inactive. There is no update to the route table needed when becoming inactive.
To prevent routing loops, the solution will not update the Alicloud Route Tables assigned to a subnet that has an activating node's network interface.
Scenarios
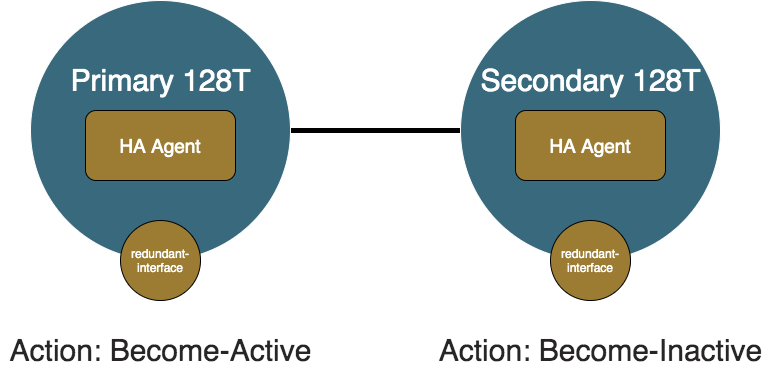
Both Healthy
In the case where both members are healthy, the primary node is preferred and set to active. The secondary node is inactive. The redundant interface on the secondary node is set provisionally down and the API Agent steers traffic towards the primary node.
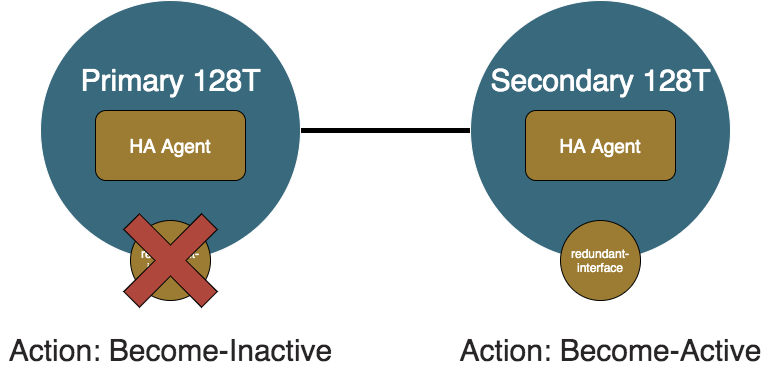
Primary Failure
When the primary node becomes unhealthy and the redundant interfaces are operationally down, the Monitoring Agent sends an unhealthy status to the local HA Agent. When the local node is deemed unhealthy, the local HA Agent sends an unhealthy message to the remote HA Agent, and notifies the internal state machine. When the primary node recognizes it is no longer fit to process traffic, it becomes inactive. The secondary node recognizes the primary node is not processing traffic, and the secondary node is healthy so the secondary node becomes active.
Primary Recovery
Now something causes the primary node to recover and the redundant-interface becomes healthy again. The healthy statuses will propagate to the primary and secondary HA Agents and they will update their internal state machines which will determine that they are back to the Both Healthy Scenario. The primary node will become active and the secondary node will become inactive.
Secondary Failure
Now let us consider after recovering, the secondary node becomes unhealthy. The primary node will recognize that it is still healthy so it will not do anything and continue to process traffic. The secondary node will also realize that it is unfit to process traffic so it will also not do anything and continue sit idle.
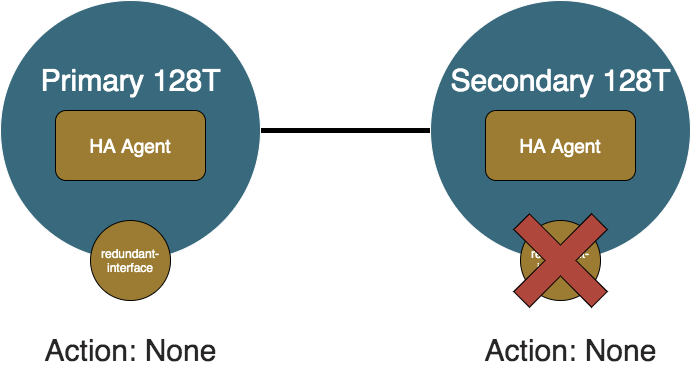
Secondary Recovery
If the problem with the secondary node resolves, then the HA Agents will update their internal state, but again since traffic is preferred to flow the same as before, both the primary and secondary will not perform any API calls to the API Agents.
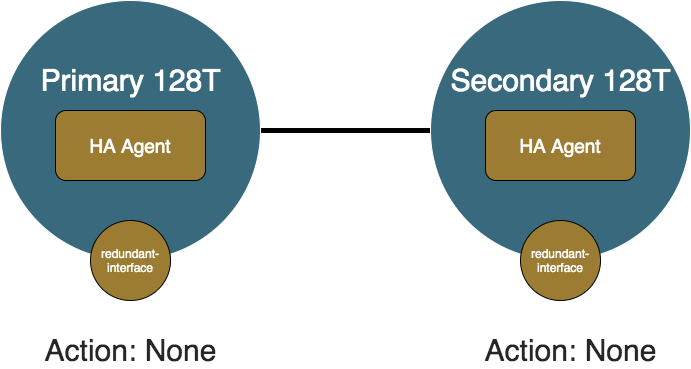
Primary Shutdown
This scenario is what will occur if the primary node were to be taken down for maintenance or failed completely. The primary node's HA Agent (and Monitoring Agent and API Agent) will be shutdown when SSR is shutdown, so it will not perform any failover operations. The secondary node will wait for peer-reachability-timeout seconds of not hearing from the primary node to determine that the secondary node is unreachable. Once the primary node is determined unreachable, the secondary HA Agent will take over and become active since it does not know if the primary node is shutdown or unreachable.

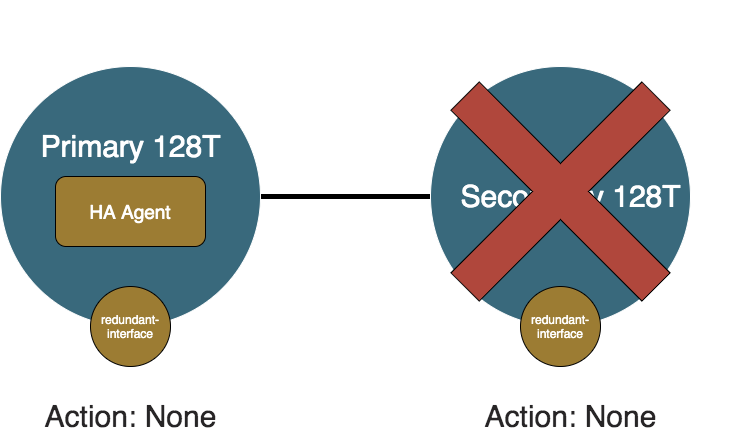
Secondary Shutdown
If the secondary node is shutdown while the primary is healthy, the primary HA Agent will deteremine the secondary node unreachable. Similar to the the Secondary Failure scenario, since the primary node is preferred, it will not do anything and continue to process traffic.
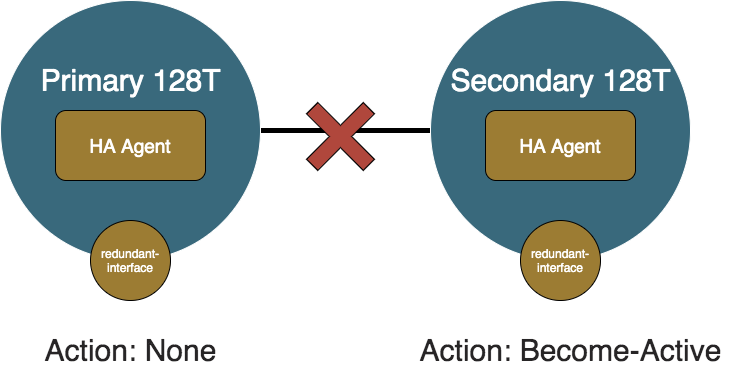
Split Brain
This is slightly distinct from the Primary Shutdown or Secondary Shutdown because both nodes and HA Agents are up and running, but the peer link between the nodes is down. In this case, both HA Agents determine that the other HA Agent is unreachable. This is indistinguisable from the other node being shutdown, so both HA Agents will determine they are in the position to take control of traffic, so whichever node was not already active will become active. This means that both nodes will have their redundant-interfaces provisionally up. For the azure-vnet solution, there will still only be one node that the route tables are pointing their routes towards due to the nature of the solution. For the azure-lb solution, both nodes will respond to the probes so traffic will be split according to the Azure Loadbalancer configuration. This situation can cause asymmetrical routing where if branch traffic comes in on the node that the solution is not pointed towards, then traffic will be sent into Azure through that node and come back in through the other node.
The split brain scenario can be identified if the peers can't reach each other which will be captured with alarms:
# show alarms
========================= ===================== ========== ======== =========== =======================================
ID Time Severity Source Category Message
========================= ===================== ========== ======== =========== =======================================
router.node:11 2020-12-16 05:40:40 CRITICAL router2 PEER Peer router2 is not reachable
router2.node2:10 2020-12-16 05:40:42 CRITICAL router PEER Peer router is not reachable
Another indicator of a split brain scenario is having the remote-status be unreachable for the state output for both members.
Split Brain Resolution
Once the health statuses are able to flow between the two nodes, the unreachable status that each Cloud HA Agent has for the other node will resolve to healthy or unhealthy. Even if the determination of whether the node is the same as it was before, each HA Agent will still set the provisional statuses and make the appropriate HTTP call on API Agent. This is because each node does not know what calls the other node made while the split brain was occurring, so it is safer to make calls even if it may not be necessary. Consider the scenario where the primary node is active and the secondary node is inactive before a split brain. When the split brain occurs, the secondary will then become active. If this is with a solution like azure-vnet, the last node to hit the API Agent will be the one that the solution point to. Thus the secondary node will be the active node from the Azure Route Table's perspective. Once the split brain is resolved, without the extra API calls, the primary would stay active without making any API calls and the secondary would become inactive. The problem with this is that the last node to trigger the API Agent was the secondary node so all branch bound traffic would be sent into interfaces that are provisionally down. The plugin solves this by reperforming API calls when it detects that the remote node goes from unreachable to not unreachable.
Configuration
Groups
A group is a collection of nodes which all share the same settings such as the solution type. In the below configuration snippet, there is an example of each of the supported solution types with the solution-specific configuration explicitly configured with their defaults. group1 has all of the solution-agnostic configuration settings explicitly configured with their defaults.
authority
cloud-redundandy-group group1
name group1
enabled true
solution-type azure-lb
additional-branch-prefix 1.1.1.1/32
additional-branch-prefix 2.2.2.2/24
up-holddown-timeout 2
peer-reachability-timeout 10
remote-health-network 169.254.180.0/24
health-interval 2
exit
cloud-redundandy-group group2
name group2
solution-type azure-vnet
include-peer-vnets false
exit
exit
| Element | Type | Properties | Description | |
|---|---|---|---|---|
| name | string | key | The name of the group to be referenced in other places. | |
| enabled | boolean | default: true | Whether the group is enabled. | |
| solution-type | enum | required | The solution to use on member nodes. Value can be one of the values in #Supported Solutions. | |
| additional-branch-prefix | list: ip-prefix | Additional ip prefixes that the member routers will control. | ||
| up-holddown-timeout | int | default: 2 | The number of seconds to wait before declaring a member up. | |
| peer-reachability-timeout | int | default: 10 | The number of seconds to wait before declaring a peer unreachable. This field must be at least twice the value of health-interval. | |
| health-interval | int | default: 2 | The interval in seconds for health reports to be collected. | |
| remote-health-network | ip-prefix | default: 169.254.180.0/24 | The ip prefix to use for inter-member health status messages. | |
| include-peer-vnets | boolean | if: solution-type = azure-vnet, default: false | Whether to include peer VNETs as part of the route table discovery algorithm. | |
| probe-port | port | if: solution-type = azure-lb, default: 12801 | The port that the Azure Loadbalancer will be sending the HTTP probes on. |
Membership
Membership is how a node declares that it is part of a group. The configuration for a membership exists under the node and is where the node-specific configuration exists.
node
cloud-redundancy-plugin-network 169.254.137.0/30
cloud-redundancy-membership group1
cloud-redundancy-group group1
priority 1
redundant-interface private
redundant-interface private2
additional-interface public1
additional-interface public2
log-level
ha-agent info
api-agent info
exit
exit
exit
...
node
cloud-redundancy-membership group1
cloud-redundancy-group group1
priority 2
redundant-interface private
exit
exit
| Element | Type | Properties | Description |
|---|---|---|---|
| cloud-redundancy-plugin-network | ip-network | default: 169.254.137.0/30 | The ip network to use for internal networking. This should only be configured when the default value conflicts with a different service in the configuration. |
| cloud-redundancy-group | reference | required | The group that this member belongs to. |
| priority | int | min-value: 1, max-value:2 | The priority of the member where lower priority has higher preference. |
| redundant-interface | list: reference | min-number: 1 | The device interfaces that will be redundant with the redundant-interfaces on the peer members. |
| additional-interface | list: reference | The device interfaces that will be considered for node health, but not considered for redundant operations. | |
| log-level/ha-agent | log-level | default: info | The log level for the HA Agent. |
| log-level/api-agent | log-level | default: info | The log level for the active API Agent. |
Nodes can only be members of one group.
Address Prefixes
Certain prefixes can be configured to be controlled by the Cloud HA SSR by tagging services with groups. The services that are tagged with a certain group will have all of their address fields added to the list of configured prefixes.
service
address 3.3.3.3
address 4.4.4.4/24
cloud-redundancy-group group1
cloud-redundancy-group azure-vnet
exit
Any additional prefixes that should be included in the controlled prefix list can be configured as additional-branch-prefixs under the group.
Generated SSR Configuration
To see a full blown configuration and the configuration it generates, look at Complete Example Configuration in the Appendix.
Validation
The following criteria need to be met in order for the cloud-ha plugin to take effect for a specific group:
- Priorities across all members in a group are unique.
- IP Network fields such as
remote-health-networkandcloud-redundancy-plugin-networkare validated to be an acceptable prefix size. - The
peer-reachability-timeoutfor a group must be at least twice the amount of time as thehealth-interval.
Please check /var/log/128technology/plugins/cloud-ha-config-generation.log on the Conductor for the errors causing the config to be invalid.
Configuration Assumptions
The components that are assumed to be setup already:
- There is at least one functioning forwarding device interface on each of the member nodes.
- There is peering between member nodes if the member nodes are not under the same router.
Cloud HA Loopback Interface
An interface with the name cloud-ha is generated for each node that is a member of an enabled group. This interface is used for the solution to communicate with the other group members and any other outside entities such as a load balancer.
Health Status Transport
To facilitate the transport of the health status between members of the same group, the plugin generates services and service routes. Services are generated to classify the health summaries that each member sends to its peers. The address that they use is an address from the network defined in remote-health-network under the group config. If the two nodes are under different routers in the configuration, then peer service routes will be generated.
Azure Load Balancer Config Generation
If the solution-type of a group is azure-lb, then the plugin will generate services and service routes to route the http probes down into the cloud-ha interface for the Azure Load Balancer API Agent to respond to.
Troubleshooting
Configuration Generation
The /var/log/128technology/persistentDataManager.log file at trace level will hold whether the configuration generation was run as well as output and return code.
Configuration generation logs can be found on the conductor under /var/log/128technology/plugins/cloud-ha-config-generation.log.
Additional configuration validation is done without causing a traditional validation error. These validation rules will cause the configuration generation to fail for just that group. If the configuration generation is not generating what is expected, then check /var/log/128technology/plugins/cloud-ha-config-generation.log for validation errors similar to these:
2020-10-09 19:54:21,190: ERROR - Validation errors occurred:
Group group1 does not have unique priorities across members: {'node2 router2': '2', 'node1 router1': '2'}
Logging
The different services on the router all log to the files captured by the glob /var/log/128technology/plugins/cloud-ha-*.log
PCLI Enhancements
To check the state of the Cloud HA solution running on the router, the plugin adds output to the show device-interface command for the cloud-ha interface. This state information is also accessible from the SSR's public REST API with a GET on /api/v1/router/<router>/node/<node>/cloud-ha/state.
State Fields
| Field | Description |
|---|---|
| is-active | Whether the HA Agent considers itself active. |
| last-activity-change | The timestamp of the last time the node called the became active or became inactive API on the API Agent. |
| first-active-interface | The name of the first interface from the list of redundant-interfaces that is healthy. |
| first-active-mac-address | The mac address of the first interface from the list of redundant-interfaces that is healthy. |
| prefixes | The list of configured prefixes. See Address Prefixes. |
| local-status | The understood state of the local node. |
| remote-status | The understood state of the remote node. |
Example output for the azure-vnet solution:
# show device-interface name cloud-ha
======================================================
node1.router1:cloud-ha
======================================================
Type: host
Forwarding: true
Mode: host
MAC Address: 92:39:db:ab:fa:e4
Admin Status: up
Operational Status: up
Redundancy Status: non-redundant
Speed: 1 Gb/s
Duplex: full
in-octets: 5653457
in-unicast-pkts: 57794
in-errors: 0
out-octets: 5648738
out-unicast-pkts: 57863
out-errors: 0
Cloud HA:
is-active: True
last-activity-change:Mon 2020-10-05 19:07:42 UTC
first-active-interface:private
first-active-mac-address:00:0d:3a:4e:17:b7
prefixes:
local-status: healthy
remote-status: healthy
Completed in 1.67 seconds
Example output for the azure-lb solution:
# show device-interface name cloud-ha
======================================================
node1.router1:cloud-ha
======================================================
Type: host
Forwarding: true
Mode: host
MAC Address: 92:39:db:ab:fa:e4
Admin Status: up
Operational Status: up
Redundancy Status: non-redundant
Speed: 1 Gb/s
Duplex: full
in-octets: 6126820
in-unicast-pkts: 62630
in-errors: 0
out-octets: 6120618
out-unicast-pkts: 62701
out-errors: 0
Cloud HA:
is-active: True
last-activity-change:Mon 2020-10-05 20:18:15 UTC
first-active-interface:private
first-active-mac-address:00:0d:3a:4e:17:b7
prefixes:
local-status: healthy
remote-status: healthy
Completed in 1.72 seconds
Example output for the alicloud-vpc solution:
# show device-interface name cloud-ha
Wed 2022-09-21 10:31:57 CST
✔ Retrieving device interface information...
======================================================
AlicloudSDWAN-HA-Router01:cloud-ha
======================================================
Type: host
Forwarding: true
Mode: host
MAC Address: ca:4d:38:ac:9b:5c
Admin Status: up
Operational Status: up
Provisional Status: up
Redundancy Status: non-redundant
Speed: 1 Gb/s
Duplex: full
in-octets: 1059977756
in-unicast-pkts: 10915259
in-errors: 0
out-octets: 1053204137
out-unicast-pkts: 10915347
out-errors: 0
Cloud HA:
is-active: True
last-activity-change:Fri 2022-09-09 10:31:15 CST
first-active-interface:LAN
first-active-mac-address:00:16:3e:10:a9:34
prefixes:
10.0.0.0/8
172.16.0.0/12
local-status: healthy
remote-status: healthy
Completed in 0.04 seconds
Systemd Services
128T-telegraf@cloud_ha_health: the instance of the monitoring agent that produces the health statuses128T-cloud-ha: the decision making Cloud HA Agent128T-azure-lband128T-azure-lb-nginx: theazure-lbspecific services128T-azure-api: theazure-vnetspecific service
Manual Failover
This should only be done in an emergency, but if the plugin is not behaving as expected, there is a script to manually set the activity status of the nodes. First you need to disable the HA Agents by running /usr/bin/t128_cloud_ha_controller disable on both nodes. This step disables the automatic API calls of the HA Agent to ensure that the following manual changes will not be overridden. Then you can run /usr/bin/t128_cloud_ha_controller become-active to become active and /usr/bin/t128_cloud_ha_controller become-inactive to become inactive. The commands should be done together at the most similar time as possible to minimize convergence time. It is better to perform the become-active first to allow traffic and then become-inactive second to disallow traffic. The HA Agents can be re-enabled with the command /usr/bin/t128_cloud_ha_controller enable.
Alarms
If the Cloud HA Agent does not come up cleanly or fails for a prolonged period of time, the cloud-ha interface will become operationally down. An alarm will be created when this happens.
Example output when the agent did not come up cleanly:
Tue 2020-10-09 16:42:50 UTC
============== ===================== ========== ============= =========== ======================================
ID Time Severity Source Category Message
============== ===================== ========== ============= =========== ======================================
combo-west:8 2020-06-30 16:32:42 critical unavailable interface Intf cloud-ha (4) operationally down
There are 0 shelved alarms
Completed in 0.10 seconds
Router Version Incompatibility
As mentioned in the Version Restrictions section, the router component of the plugin will only install on SSR versions which support the provisional device interface state. This will be apparent to the user if the router component is not being setup and show assets indicates an error similar to:
Error:
Problem: conflicting requests
- nothing provides 128T-device-interface-api(1.0) needed by 128T-cloud-ha-router-1.1.0-1.x86_64
The router will need to be upgraded to a compatible version. Compatible versions can be listed with dnf list --whatprovides 128T-device-interface-api(1.0).
Appendix
Health Status Transport
With the example configuration, we will generate the services below:
service cloud-ha-service-group1-2
name cloud-ha-service-group1-2
applies-to router
type router
router-name router1
router-name router2
exit
security internal
address 169.254.180.2
access-policy cloud-ha
source cloud-ha
permission allow
exit
share-service-routes false
exit
service cloud-ha-service-group1-1
name cloud-ha-service-group1-1
applies-to router
type router
router-name router1
router-name router2
exit
security internal
address 169.254.180.1
access-policy cloud-ha
source cloud-ha
permission allow
exit
share-service-routes false
exit
Corresponding service routes to route them into the cloud-ha interface will be generated.
router router1
service-route cloud-ha-service-route-group1-1
name cloud-ha-service-route-group1-1
service-name cloud-ha-service-group1-1
nat-target 169.254.137.2
exit
exit
router router2
service-route cloud-ha-service-route-group1-2
name cloud-ha-service-route-group1-2
service-name cloud-ha-service-group1-2
nat-target 169.254.137.2
exit
exit
If the two nodes are under different routers in the configuration, this would produce service routes:
router router1
service-route cloud-ha-peer-service-route-group1-2
name cloud-ha-peer-service-route-group1-2
service-name cloud-ha-service-group1-2
peer router2
exit
exit
router router2
service-route cloud-ha-peer-service-route-group1-1
name cloud-ha-peer-service-route-group1-1
service-name cloud-ha-service-group1-1
peer router1
exit
exit
Azure Loadbalancer Configuration Generation
With the example configuration, this would result in the following services being generated:
service cloud-ha-lb-probe-service-group1-2
name cloud-ha-lb-probe-service-group1-2
applies-to router
type router
router-name router2
exit
security internal
transport tcp
protocol tcp
port-range 12801
start-port 12801
exit
exit
address 1.1.1.2
access-policy private
source private
permission allow
exit
share-service-routes false
exit
service cloud-ha-lb-probe-service-group1-1
name cloud-ha-lb-probe-service-group1-1
applies-to router
type router
router-name router1
exit
security internal
transport tcp
protocol tcp
port-range 12801
start-port 12801
exit
exit
address 1.1.1.1
access-policy private
source private
permission allow
exit
share-service-routes false
exit
There would also be corresponding service routes generated:
router router1
service-route cloud-ha-lb-probe-service-route-group1-1
name cloud-ha-lb-probe-service-route-group1-1
service-name cloud-ha-lb-probe-service-group1-1
nat-target 169.254.137.2
exit
exit
router router2
service-route cloud-ha-lb-probe-service-route-group1-2
name cloud-ha-lb-probe-service-route-group1-2
service-name cloud-ha-lb-probe-service-group1-2
nat-target 169.254.137.2
exit
exit
Complete Example Configuration #1 for azure-lb
Below is an example of a complete, but minimal configuration entered by the user.
This example configuration is good to understand all of the concepts but should not be used on a system as is.
This example uses azure-lb since it results in a superset of the configuration generated azure-vnet. If you are interested in azure-vnet, then ignore the probe-specific services and service routes in the generated config.
config
authority
tenant private
exit
cloud-redundandy-group group1
name group1
solution-type azure-lb
exit
router router1
node node1
device-interface private
name private
network-interface privateintf
name privateintf
tenant private
address 1.1.1.1
ip-address 1.1.1.1
prefix-length 24
gateway 1.1.1.3
exit
exit
exit
device-interface intracloud
name intracloud
network-interface intracloudintf
name intracloudintf
inter-router-security internal
neighborhood intracloud
name intracloud
topology mesh
exit
address 2.2.2.1
ip-address 2.2.2.1
prefix-length 24
gateway 2.2.2.3
exit
exit
exit
cloud-redundancy-membership group1
cloud-redundancy-group group1
priority 1
redundant-interface private
exit
exit
exit
router router2
node node1
device-interface private
name private
network-interface privateintf
name privateintf
tenant private
address 1.1.1.2
ip-address 1.1.1.2
prefix-length 24
gateway 1.1.1.3
exit
exit
exit
device-interface intracloud
name intracloud
network-interface intracloudintf
name intracloudintf
inter-router-security internal
neighborhood intracloud
name intracloud
topology mesh
exit
address 2.2.2.2
ip-address 2.2.2.2
prefix-length 24
gateway 2.2.2.3
exit
exit
exit
cloud-redundancy-membership group1
cloud-redundancy-group group1
priority 2
redundant-interface private
exit
exit
exit
exit
exit
Upon commit, the plugin will generate other configuration as shown below:
config
authority
tenant cloud-ha
name cloud-ha
description "Auto-generated tenant for cloud ha"
exit
router router1
node node1
device-interface cloud-ha
name cloud-ha
description "Auto-generated host KNI interface for cloud ha"
type host
network-interface cloud-ha-intf
name cloud-ha-intf
type external
tenant cloud-ha
source-nat true
address 169.254.137.1
ip-address 169.254.137.1
prefix-length 30
gateway 169.254.137.2
exit
exit
exit
exit
service-route cloud-ha-service-route-group1-1
name cloud-ha-service-route-group1-1
service-name cloud-ha-service-group1-1
nat-target 169.254.137.2
exit
service-route cloud-ha-peer-service-route-group1-2
name cloud-ha-peer-service-route-group1-2
service-name cloud-ha-service-group1-2
peer router2
exit
service-route cloud-ha-lb-probe-service-route-group1-1
name cloud-ha-lb-probe-service-route-group1-1
service-name cloud-ha-lb-probe-service-group1-1
nat-target 169.254.137.2
exit
exit
router router2
node node1
device-interface cloud-ha
name cloud-ha
description "Auto-generated host KNI interface for cloud ha"
type host
network-interface cloud-ha-intf
name cloud-ha-intf
type external
tenant cloud-ha
source-nat true
address 169.254.137.1
ip-address 169.254.137.1
prefix-length 30
gateway 169.254.137.2
exit
exit
exit
exit
service-route cloud-ha-service-route-group1-2
name cloud-ha-service-route-group1-2
service-name cloud-ha-service-group1-2
nat-target 169.254.137.2
exit
service-route cloud-ha-peer-service-route-group1-1
name cloud-ha-peer-service-route-group1-1
service-name cloud-ha-service-group1-1
peer router1
exit
service-route cloud-ha-lb-probe-service-route-group1-2
name cloud-ha-lb-probe-service-route-group1-2
service-name cloud-ha-lb-probe-service-group1-2
nat-target 169.254.137.2
exit
exit
service cloud-ha-lb-probe-service-group1-2
name cloud-ha-lb-probe-service-group1-2
applies-to router
type router
router-name router2
exit
security internal
transport tcp
protocol tcp
port-range 12801
start-port 12801
exit
exit
address 1.1.1.2
access-policy private
source private
permission allow
exit
share-service-routes false
exit
service cloud-ha-lb-probe-service-group1-1
name cloud-ha-lb-probe-service-group1-1
applies-to router
type router
router-name router1
exit
security internal
transport tcp
protocol tcp
port-range 12801
start-port 12801
exit
exit
address 1.1.1.1
access-policy private
source private
permission allow
exit
share-service-routes false
exit
service cloud-ha-service-group1-2
name cloud-ha-service-group1-2
applies-to router
type router
router-name router1
router-name router2
exit
security internal
address 169.254.180.2
access-policy cloud-ha
source cloud-ha
permission allow
exit
share-service-routes false
exit
service cloud-ha-service-group1-1
name cloud-ha-service-group1-1
applies-to router
type router
router-name router1
router-name router2
exit
security internal
address 169.254.180.1
access-policy cloud-ha
source cloud-ha
permission allow
exit
share-service-routes false
exit
exit
exit
Part of Example Configuration #2 for alicloud-vpc after auto generation.
Below is a sample running configuration for a node and a service.
Use the following configuration as an example only - it should not be used on a system as is.
node AlicloudSDWAN-HA-Router01 name AlicloudSDWAN-HA-Router01 asset-id iZwz96to20bbnnb
device-interface WAN name WAN pci-address 0000:00:04.0
network-interface WAN name WAN global-id 17
neighborhood ChinaUnicom name ChinaUnicom external-nat-address 119.23.200.200 vector wan1
path-mtu-discovery enabled true exit exit inter-router-security internal dhcp v4 exit exit
device-interface LAN name LAN pci-address 0000:00:05.0 enabled true
network-interface LAN name LAN global-id 18
neighborhood ALICLOUD name ALICLOUD exit inter-router-security internal dhcp v4 exit exit
device-interface farbic name farbic pci-address 0000:00:06.0
network-interface fabric name fabric global-id 19
neighborhood intracloud name intracloud topology mesh
path-mtu-discovery enabled true exit exit inter-router-security internal dhcp v4 exit exit
device-interface cloud-ha name cloud-ha description "Auto generated device interface cloud-ha" type host
network-interface cloud-ha-intf name cloud-ha-intf global-id 27 type external tenant cloud-ha source-nat true
address 169.254.137.1 ip-address 169.254.137.1 prefix-length 30 gateway 169.254.137.2 exit exit exit exit
service-route Alicloud-HA-test name Alicloud-HA-test service-name Alicloud-HA-test vector peer1
next-hop AlicloudSDWAN-HA-Router01 LAN node-name AlicloudSDWAN-HA-Router01 interface LAN vector peer1 exit exit
service-route AliCloud-HA-test2 name AliCloud-HA-test2 service-name Alicloud-HA-test vector peer2 peer AlicloudSDWAN-HA-Router02 exit
service-route cloud-ha-service-route-alicloud-1 name cloud-ha-service-route-alicloud-1 service-name cloud-ha-service-alicloud-1 nat-target 169.254.137.2 exit
service-route cloud-ha-peer-service-route-alicloud-2 name cloud-ha-peer-service-route-alicloud-2 service-name cloud-ha-service-alicloud-2 peer AlicloudSDWAN-HA-Router02 exit exit
Release Notes
Release 3.0.0
Issues Fixed
- PLUGIN-768 Support the Cloud HA plugin in SSR versions
5.1.0and greater.