Configuring Dual Node High Availability
The SSR provides significant flexibility for high availability configurations. The SSR can deploy multiple software instances (referred to as nodes) within the same installation, providing high availability across router nodes. Like traditional routers, the SSR can also be deployed as a single router instance on multiple platforms, with high availability configured in a dual-router configuration.
This document describes how to configure dual-node high availability. In addition to the shared MAC interface method of dual node high availability, the release of the 5.4 software includes VRRP as a configuration option.
A new service route parameter introduced in version 5.4, enable-failover, provides stateful failover on the dual node HA configuration.
Requirements
Configuring high availability in a shared-interface configuration requires that two SSR routing nodes have at least one device-interface that is shared between them. Shared interfaces are configured on both nodes, but are active on only one node at a time. These shared interfaces must be in the same L2 broadcast domain; this is because the SSR uses gratuitous ARP messages to announce an interface failover, so that it may receive packets in place of its counterpart.
The two SSR router nodes that make up a high availability pair must be collocated due to latency sensitivities for the information that they synchronize between themselves.
Before You Begin
There are several things to be mindful of before configuring HA; the two nodes must be informed that they are part of a high availability set, and they must have a dedicated interface between themselves for synchronizing state information about active sessions. These steps will be covered in this section.
Configuration Change Operations
For High Availability (HA) configurations, all configuration edit and commit operations must be done on only one node. A severe, but very rare race condition may occur if changes to the configuration are made concurrently on both nodes of the HA router or conductor; the generated configuration will be lost upon commit. This applies to all methods of editing: PCLI, Web GUI, or external API’s (NETCONF or REST).
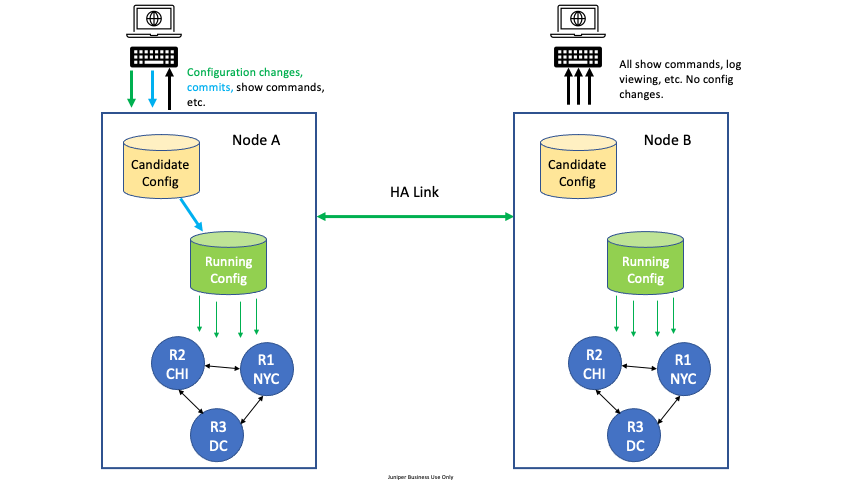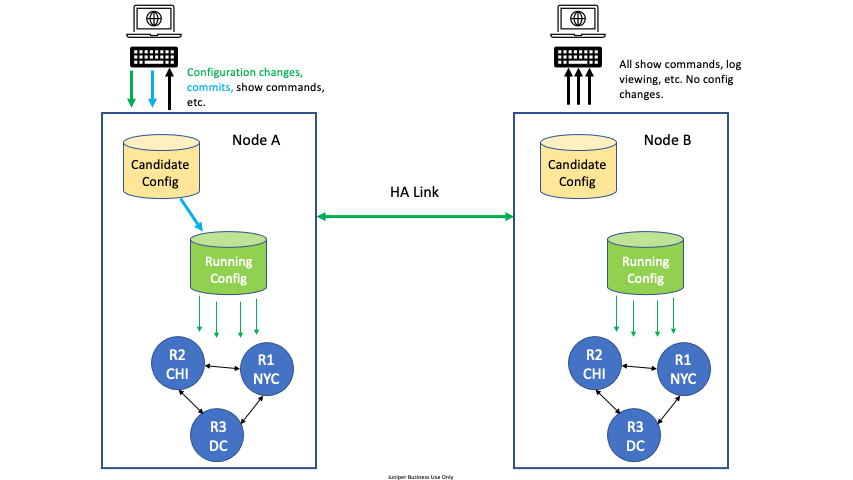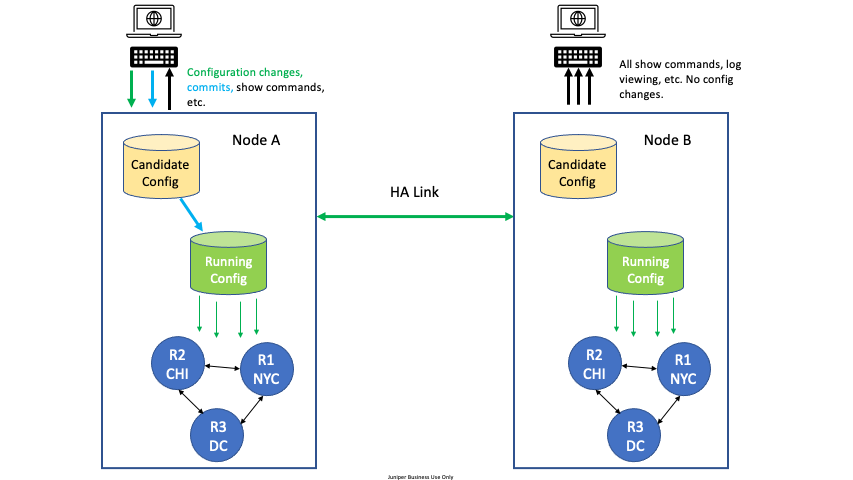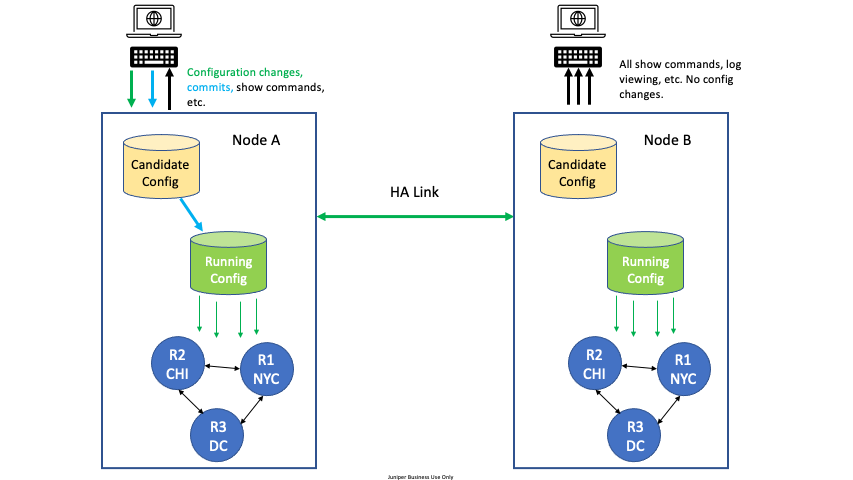
To avoid this situation, designate one node as the edit node. For example, in an HA configuration with two nodes, DataCenter Node A and DataCenter Node B, designate DataCenter Node A as the edit node. All configuration changes are made on Node A. All other commands can be run on Node B, but no configuration changes or commits, whether from the GUI, PCLI, or an API, are made from Node B.
This issue is resolved in release 5.3.0, but affects all prior releases.
Exporting the Candidate Configuration
The Candidate configuration is not synchronized between nodes and is not stored on disk.
Configuration changes are always made to a candidate configuration. In earlier releases the candidate configuration was stored on disk and would persist through product reboots. Beginning with 5.3, the candidate configuration is not saved to disk and will not persistent through reboot.
Additionally, the candidate configuration is no longer synchronized between HA nodes. Beginning with 5.3, only the running configuration is synchronized between nodes.
Use the export config command to save your configuration changes while working, especially if you are performing multiple changes. Changes to the running configuration are only be made when the configuration is committed.
Clock Synchronization
Because highly available nodes synchronize time-series data, it is critical that the two nodes that comprise an HA pair have synchronized clocks. It is sufficient to manually synchronize the clocks until SSR software is installed, after which point NTP (Network Time Protocol) can be used to automatically synchronize the clocks.
Within the SSR configuration, you should configure NTP servers within authority > router > system > ntp.
Confirm NTP
To confirm that you have NTP configured, use the command show config running as shown here:
admin@labsystem2.newton# show config running authority router newton system ntp
config
authority
router newton
name newton
system
ntp
server time.nist.gov
ip-address time.nist.gov
exit
exit
exit
exit
exit
exit
To confirm that NTP is synchronized, use the show ntp command and confirm that at least one NTP server is in the active state (some columns have been removed for display purposes):
admin@labsystem2.newton# show ntp
Sat 2019-01-26 06:54:29 EST
Node: labsystem2
======== ================== ========= ========= ====== ======== ======== ========
Status Time Source Ref. ID Stratum Poll Delay Offset Jitter
======== ================== ========= ========= ====== ======== ======== ========
active *time-b-wwv.nist .NIST. 1 1024 68.905 -0.981 2.524
Completed in 0.19 seconds
Migrating from Standalone to HA
For an established standalone router of one node, converting it to be highly available requires configuring a second node within the SSR configuration (PCLI or GUI).
Converting an existing router from standalone to HA will require downtime, and is therefore only to be undertaken during a maintenance window, as applicable.
Adding a second node requires configuring another node container within the router. This node will contain one or more shared interfaces, which will protect the router from failure modes when interfaces, links, or a node fails. Configuring shared interfaces is covered later in this document.
Follow the steps in Non-forwarding HA Interfaces to provision an interface to connect between peer SSR nodes.
Configuring the Shared Interface(s)
For systems configured prior to release 5.4, Dual Node High Availability can be configured using a shared MAC interface, and is described below. For systems configured on release 5.4 and later, High Availability can be configured using VRRP. See High Availability Using VRRP for information about using VRRP for dual-node failover.
A highly available router is comprised of exactly two routing nodes within the same router container. (Configuring two routers, each comprised of one node, cannot be made highly available.) Additionally, the routers must have at least one shared interface in common.
Configuring the basic properties of the two nodes is described elsewhere in this documentation. For high availability, the crucial step is identifying the interfaces that are to be shared between them. This is done by establishing a common Layer 2 address, known as a MAC address, that is maintained by the active node in the pair. For example, when node1 of the pair has active control over the interface, it responds to ARP requests for the addresses on the interface with the shared MAC address, whereas node2 will not. The configuration element for this MAC address is the shared-phys-address, within the device-interface element.
The shared-phys-address is simply a series of six octets, that is unique on a given broadcast domain. (The SSR Conductor also enforces that the shared-phys-address be unique among all routers within an Authority.) There are no hard and fast rules for creating "globally unique" MAC addresses; there are, however, many websites available that will generate random values. Again, since these MAC addresses are only used on a broadcast domain, they do not need to be globally unique to suit the SSR router's needs. The shared-phys-address is configured using the format "00:00:00:00:00:00."
When configuring shared-MAC failover, it is important to use a locally administered MAC address. The use of a universally administered MAC causes inconsistent session establishment issues. These can be difficult to troubleshoot.
For more information about locally and universally administered MAC addresses, please see [MAC Addresses.](https://en.wikipedia.org/wiki/MAC_address#Universal_vs._local_(U/L_bit)
Configuring the same shared-phys-address on two different interfaces (one per node in the high availability pair) informs the SSR that you wish to have the interfaces protect one another. This in turn causes the SSR to assign all corresponding pairs of network-interfaces that belong to this shared interface the same common global ID. (I.e., each network-interface on a node will have a unique global ID, but each counterpart network-interface on a highly available node will have the same global ID.) The global ID is an internal identifier, used by the SSR, to refer to the shared interface.
About the Global ID
Each network-interface within a SSR configuration has a global ID assigned to it. The term "global" refers to the value being global across two nodes of a router; it is not uniquely global across an Authority. Each router within an authority can share the same global ID. When two nodes share an interface for high availability, each network-interface pair, one per node, that fails over to another network-interface on the paired node is assigned the same global ID.
admin@node1.router1 (device-interface[name=wan])# show
name wan
description "WAN interface, port 0"
type ethernet
pci-address 0000:00:14.0
link-settings auto
enabled true
forwarding true
shared-phys-address 12:81:28:00:00:AA
network-interface vlan0
name vlan0
global-id 1
This value is also present in the output of show rib, where it is the trailing value within each RIB entry:
admin@node1.router1# show rib
Mon 2019-01-07 10:53:19 EST
Codes: K - kernel route, C - connected, S - static, R - RIP,
O - OSPF, I - IS-IS, B - BGP, E - EIGRP, N - NHRP,
T - Table, v - VNC, V - VNC-Direct, A - Babel, D - SHARP,
F - PBR,
> - selected route, * - FIB route
C>* 10.0.128.0/17 is directly connected, g2, 00:46:05
C * 169.254.127.126/31 is directly connected, g4294967293, 00:43:58
C>* 169.254.127.126/31 is directly connected, g4294967294, 00:46:06
C>* 169.254.255.2/31 is directly connected, g3, 00:44:15
C>* 192.0.2.0/24 is directly connected, g1, 00:46:05
The g1 value in the line above refers to the interface assigned with global-id value 1.
Network Interface Consistency
When configuring shared interfaces, it is crucial that the network-interface elements within a shared device-interface are identical. This is to prevent any behavioral changes when ownership of a shared interface changes from one node to its counterpart. The configuration validation step prevents committing configuration changes when the network-interface elements are not identical.
Confirming that Interfaces are Shared
Once you have configured two device-interface elements on individual nodes within a router for high availability, the show device-interface summary command will identify which devices are redundant (shared) within the pair, as well as whether the interface is active or standby (or non-redundant, for interfaces that do not have a counterpart).
admin@node1.router1# show device-interface summary
Mon 2019-01-07 10:45:11 EST
================= ============== ============= =================== ===================
Name Admin Status Oper Status Redundancy Status MAC Address
================= ============== ============= =================== ===================
node1:wan up up active 00:90:0b:54:f6:86
node1:lan up up active 00:90:0b:54:f6:87
Completed in 0.36 seconds
In this sample output, the interfaces on node1 are active from a redundancy standpoint. Adding the optional argument node all to the command will show all interfaces on the nodes that comprise the router:
admin@node1.router1# show device-interface node all summary
Mon 2019-01-07 10:49:09 EST
================= ============== ============= =================== ===================
Name Admin Status Oper Status Redundancy Status MAC Address
================= ============== ============= =================== ===================
node1:wan up up active 00:90:0b:54:f6:86
node1:lan up up active 00:90:0b:54:f6:87
node2:wan up up standby 00:90:0b:73:88:40
node2:lan up up standby 00:90:0b:73:88:41
Completed in 0.66 seconds
Configuring the Fabric Interface
An optional, but common inclusion in highly available routers is a fabric interface, also known as a "dogleg" interface. Named to evoke the imagery of a fabric backplane or midplane of a chassis-based router, the fabric interface is a forwarding interface between two nodes in a router, and is used when the ingress interface and egress interface for a given session are active on different nodes.
Fabric interfaces are not required for simple active/standby deployments where the two nodes are mirror images of one another (e.g., each WAN interface and LAN interface is protected using shared interfaces). It does offer an additional protection against failure even in these active/standby setups: the double failure of a LAN port on node 1 and a WAN port on node 2. For deployments where Ethernet ports are not at a premium, a fabric interface is strongly recommended.
device-interface internode
name internode
description "Direct connect between nodes, port 2"
type ethernet
pci-address 0000:00:14.2
forwarding true
network-interface fabric
name fabric
global-id 3
description "Fabric link between nodes"
type fabric
address 169.254.255.2
ip-address 169.254.255.2
prefix-length 31
exit
exit
exit
Configuring Redundancy Groups
Redundancy groups are sets of interfaces that share fate, such that if one of the interfaces in the group fails, leadership of all interfaces in the group will be relinquished to the counterpart node in the router. Redundancy groups are required when the two nodes in a router do not have a fabric interface between them. If this were the case, the potential exists for a situation where the active LAN interface is on node 1 and the active WAN interface is on node 2, with no way to transmit packets from node 1 to node 2.
When configuring high availability using VRRP, redundancy groups are not configured/needed.
While redundancy groups are most commonly found in legacy deployments (i.e., those that predate the SSR's introduction of the fabric interface), they are still useful in simple HA deployments. Furthermore, the redundancy group affords administrators the ability to assert a preference for which node is active in an HA pair in the "sunny day" scenario where no interfaces are administratively or operationally down.
Generally, you will configure two nodes that each have a set of forwarding interfaces (for illustrative purposes, assume an interface on an internal network named lan and an interface on an external network named wan). Each node requires a redundancy-group that containing a pair of internal and external interfaces, as is seen in the following example:
redundancy-group grp-node1
name grp-node1
member node1 wan
node node1
device-id wan
exit
member node1 lan
node node1
device-id lan
exit
priority 50
exit
redundancy-group grp-node2
name grp-node2
member node2 wan
node node2
device-id wan
exit
member node2 lan
node node2
device-id lan
exit
priority 25
exit
In this example, our two redundant nodes (node1 and node2) each have two interfaces contained within part of the redundancy-group. Note that each group collects the interfaces for a node, not interfaces that share a global-id.
It is considered a best practice to configure different priority values on each redundancy group. The group with the higher priority value is active, or primary. When configuring redundancy-groups the failover of the systems is “revertive”; the group with the higher priority is active unless it experiences a failure. When that failure is restored it becomes active again.
If two redundancy-groups are configured with the same priority value, the SSR router will select an active member using an internal election algorithm, which is not guaranteed to be revertive in the event of a failure.
Service Route Redundancy
Available with SSR Version 5.4 and higher.
enable-failover on the service-route:
Service Routes are used to influence traffic destinations for services. By enabling failover on the service route, failover includes the existing sessions, eliminating the lag time previously encountered as those sessions were re-established. Service route redundancy is not exclusive to dual node, high availability configurations. It is configured as shown below.
To enable existing sessions to failover between the nodes, enable-failover is configured on both the service-routes test-1_intf13_route-0 and test-2_intf113_route-0. Any generated peer service-routes will inherit this property as well.
service-route test-1_intf13_route-0
name test-1_intf13_route-0
service-name east-0
vector primary
enable-failover true
next-hop test-1 intf13
node-name test-1
interface intf13
gateway-ip 172.16.4.4
exit
reachability-detection
enabled true
enforcement true
detection-window 10
hold-down 60
reachability-profile profile-1
probe-type always
probe foo
name foo
enabled true
icmp-probe-profile icmp-profile-0
exit
exit
exit
service-route test-2_intf113_route-0
name test-2_intf113_route-0
service-name east-0
vector secondary
enable-failover true
next-hop test-2 intf113
node-name test-2
interface intf113
gateway-ip 172.16.4.5
exit
reachability-detection
enabled true
enforcement true
detection-window 10
hold-down 60
reachability-profile profile-1
probe-type always
probe foo
name foo
enabled true
icmp-probe-profile icmp-profile-0
exit
exit
exit
Using vector to Define the Primary Node
The use of a vector is not exclusive to dual node, high availability configurations. It is configured as shown below.
To define the primary and standby nodes in the HA configuration, configure a vector on the service-route and a priority on the service-policy.
vector- configured on the service route
service-route
name wan1-route
service-name wan-service
vector red
priority 100
next-hop
node node1
interface wan1-intf
- The
priorityvalue of thevectordefined in theservice-policy:
service-policy netcat-policy
name netcat-policy
service-class netcat-class
lb-strategy hunt
vector red
name red
priority 100
exit
vector blue
name blue
priority 90
The vector and the associated priority can then be assigned to one or more next hops within the service route, providing a primary and secondary path for failover and high availability.
service-route
name wan1-route
service-name wan-service
next-hop
vector red
node node1
interface wan1-intf
next-hop
vector blue
node node1
interface wan2-int
High Availability Using VRRP
In dual-node HA configurations, VRRP is configurable on either the device-interface or the network-interface.
Configuring VRRP on the Device Interface
When a failover event is encountered, device interface level VRRP will fail over an entire device interface, including all network interfaces under that device interface. VRRP reduces failover time, and when configured with service-route failover, will preserve sessions.
Configure VRRP on the wan and lan interfaces of node 1. In this example node 1 is set as the active node (set with the higher priority), and node 2 is configured as the standby node.
node node1
name node1
description "Node 1 of HA pair"
device-interface wan
name wan
description "WAN interface, port 0"
type ethernet
pci-address 0000:00:14.0
link-settings auto
enabled true
forwarding true
vrrp
enabled true
vrid 128
priority 100
advertisement-interval 250
exit
network-interface vlan0
name vlan0
global-id 1
device-interface lan
name lan
description "LAN interface, port 1"
type ethernet
pci-address 0000:00:14.1
link-settings auto
enabled true
forwarding true
vrrp
enabled true
vrid 95
priority 100
advertisement-interval 250
exit
network-interface vlan100
name vlan100
global-id 2
vlan 100
type external
inter-router-security internal
Node 2 lan and wan interfaces are configured similarly, however the priority is lower to indicate it is the standby node.
node node2
name node2
description "Node 2 of the HA pair"
device-interface wan
name wan
description "WAN interface, port 0"
type ethernet
pci-address 0000:00:14.0
link-settings auto
enabled true
forwarding true
vrrp
enabled true
vrid 128
priority 99
advertisement-interval 250
exit
network-interface vlan0
name vlan0
global-id 1
device-interface lan
name lan
description "LAN interface, port 1"
type ethernet
pci-address 0000:00:14.1
link-settings auto
enabled true
forwarding true
vrrp
enabled true
vrid 95
priority 99
advertisement-interval 250
exit
network-interface vlan100
name vlan100
global-id 2
vlan 100
type external
inter-router-security internal
Configuring VRRP on the Network Interface
The vrrp field under network-interface has the following configuration parameters:
network-interface lan2
vrrp
enabled <true/false>
priority <1-255>
vrid <1-255>
advertisement-interval <100-40950>
exit
With this configuration option, network interfaces can have VRRP enabled independent of one another, allowing redundant interfaces to fail over when necessary, and unaffected interfaces to continue operation. For example, perhaps there is one interface that does not need to failover, but two that do. VRRP can be configured on two of the network-interfaces, and disabled on the third interface. Or, if it is desirable to have a VLAN to go over node0 as primary and another VLAN go over node1 as primary, this can be defined in the configuration by specifying the priority.
In the configuration example below:
- lan1 takes node0 as primary and fails over to node1
- lan2 takes node1 as primary and fails over to node0
- lan3 only exists on node0 and does not failover
node0 Node1
device-interface lan device-interface lan
name lan name lan
pci-address xxx pci-address xxx
network-interface lan1 network-interface lan1
vrrp vrrp
enabled true enabled true
priority 20 priority 10
vrid 1 vrid 1
exit exit
name lan1 name lan1
vlan 1 vlan 1
address xxxx address xxxx
exit exit
Network-interface lan2 network-interface lan2
Vrrp vrrp
enabled true enabled true
priority 10 priority 20
vrid 15 vrid 15
exit exit
name lan2 name lan2
Vlan 2 vlan 2
address xxxxx address xxxx
network-interface lan3
name lan3
vlan 3
address xxx
exit
Show Commands
Use the show network interface command to display active standby at vlan level, and the show network-interface redundancy command to show redundancy status of network-interfaces.
Configuration Considerations
- VRRP can be enabled only on one of the vlans, but the state of VRRP run on that vlan affects the whole device interface. The vrrp vlan will default to
vlan 0, but is user configurable to a different vlan. - VRRP cannot be enabled on a vlan that has DHCP.
- If DHCP needs to be supported on a VRRP enabled device interface, then VRRP must be enabled on another vlan with a static IP.
Shared-MAC Failover Sample Configuration
Below is a sample, minimal configuration for which shows the inclusion of both a fabric interfaces as well as redundancy-groups. This topology consists of 4 interfaces per node. 1 LAN, 1 WAN, 1 Fabric dog-leg, and 1 Fabric forwarding interface.
When configuring shared-MAC failover, it is important to use a locally administered MAC address, as shown in the updated configuration below. The use of a universally administered MAC causes inconsistent session establishment issues. These can be difficult to troubleshoot.
For more information about locally and universally administered MAC addresses, please see MAC Addresses
This is an example of a pre-5.4 configuration using the shared-mac failover.
config
authority
name 128technology
dynamic-hostname interface-{interface-id}.{router-name}.{authority-name}
router router1
name router1
location-coordinates +42.35972+116.17917/
description "HA branch office router, Lanner 7573B"
system
contact admin@128technology.com
log-level info
ntp
server 132.163.97.1
ip-address 132.163.97.1
exit
exit
exit
node node1
name node1
description "Node 1 of HA pair"
device-interface wan
name wan
description "WAN interface, port 0"
type ethernet
pci-address 0000:00:14.0
link-settings auto
enabled true
forwarding true
shared-phys-address 12:81:28:00:00:AA
network-interface vlan0
name vlan0
global-id 1
neighborhood internet
name internet
topology spoke
exit
inter-router-security internal
address 192.0.2.1
ip-address 192.0.2.1
prefix-length 24
exit
exit
exit
device-interface lan
name lan
description "LAN interface, port 1"
type ethernet
pci-address 0000:00:14.1
link-settings auto
enabled true
forwarding true
shared-phys-address 12:81:28:00:00:BB
network-interface vlan100
name vlan100
global-id 2
vlan 100
type external
inter-router-security internal
address 10.0.128.1
ip-address 10.0.128.1
prefix-length 17
exit
exit
exit
device-interface internode
name internode
description "Direct connect between nodes, port 2"
type ethernet
pci-address 0000:00:14.2
forwarding true
network-interface fabric
name fabric
global-id 3
description "Fabric link between nodes"
type fabric
address 169.254.255.2
ip-address 169.254.255.2
prefix-length 31
exit
exit
exit
device-interface ha-fabric
name ha-fabric
type ethernet
pci-address 0000:00:14.3
forwarding false
network-interface peer-fabric-intf
name peer-fabric-intf
type fabric
address 172.16.1.1
ip-address 172.16.1.1
prefix-length 24
exit
exit
exit
exit
node node2
name node2
description "Node 2 of the HA pair"
device-interface wan
name wan
description "WAN interface, port 0"
type ethernet
pci-address 0000:00:14.0
link-settings auto
enabled true
forwarding true
shared-phys-address 12:81:28:00:00:AA
network-interface vlan0
name vlan0
global-id 1
neighborhood internet
name internet
topology spoke
exit
inter-router-security internal
address 192.0.2.1
ip-address 192.0.2.1
prefix-length 24
exit
exit
exit
device-interface lan
name lan
description "LAN interface, port 1"
type ethernet
pci-address 0000:00:14.1
link-settings auto
enabled true
forwarding true
shared-phys-address 12:81:28:00:00:BB
network-interface vlan100
name vlan100
global-id 2
vlan 100
type external
inter-router-security internal
address 10.0.128.1
ip-address 10.0.128.1
prefix-length 17
exit
exit
exit
device-interface internode
name internode
description "Direct connect between nodes, port 2"
type ethernet
pci-address 0000:00:14.2
forwarding true
network-interface fabric
name fabric
global-id 3
description "Fabric link between nodes"
type fabric
address 169.254.255.3
ip-address 169.254.255.3
prefix-length 31
exit
exit
exit
exit
device-interface ha-fabric
name ha-fabric
type ethernet
pci-address 0000:00:14.3
forwarding false
network-interface peer-fabric-intf
name peer-fabric-intf
type fabric
address 172.16.1.2
ip-address 172.16.1.2
prefix-length 24
exit
exit
exit
redundancy-group grp-node1
name grp-node1
member node1 wan
node node1
device-id wan
exit
member node1 lan
node node1
device-id lan
exit
priority 50
exit
redundancy-group grp-node2
name grp-node2
member node2 wan
node node2
device-id wan
exit
member node2 lan
node node2
device-id lan
exit
priority 25
exit
service-route rte_default-route
name rte_default-route
service-name default-route
next-hop node1 vlan0
node-name node1
interface vlan0
exit
exit
exit
service default-route
name default-route
description "Default route"
scope public
address 0.0.0.0/0
exit
exit
exit